
Few companies ever operate at a scale as massive as Google’s. And in 2006, with a codebase spanning billions of lines and tens of thousands of engineers making constant changes, it was only natural for them to explore the notion of their own in-house build system.
In short, they needed a scalable build tool that was:
- Fast, providing quick feedback loops to keep developers productive.
- Reproducible, ensuring consistent results across machines and environments.
- Configurable, adapting to a wide range of workflows — from backend services to mobile apps to frontend builds.
- Extensible, allowing teams to define custom build rules tailored to their unique infrastructure and multiple languages.
- Well-integrated, with support for IDEs, command-line workflows, and CI/CD pipelines.
These needs gave birth to a system known as Blaze, Google’s very own internal build solution.
Then in March 2015, Google open-sourced Blaze under a new name: Bazel — bringing the same core principles to the wider developer community.
Bazel: The Build System that Scales
At the crux of Bazel’s design lies an important philosophy: determinism.
This means, given the same inputs, Bazel will produce the same build outputs (every single time). To guarantee this level of consistency, Bazel relies on hermetic builds: fully isolated actions that run in sandboxed environments.
Put simply, Bazel build processes are made insensitive to differences in the host environment, such as software versions or installed libraries. While not guaranteed by default, this isolation can be achieved by explicitly declaring dependencies and using custom toolchains to avoid relying on host-provided components.
The result? Predictable builds (assuming proper configuration) that behave the same everywhere. This foundational principle serves as the bedrock of Bazel’s functionality, setting the stage for everything else.
Caching and Incremental Builds
With Bazel’s isolated build model, every input is meticulously tracked and hashed down to the byte. These hashes allow Bazel to detect whether a build action has been performed before — and if it has, Bazel simply skips the work and reuses the previous results.
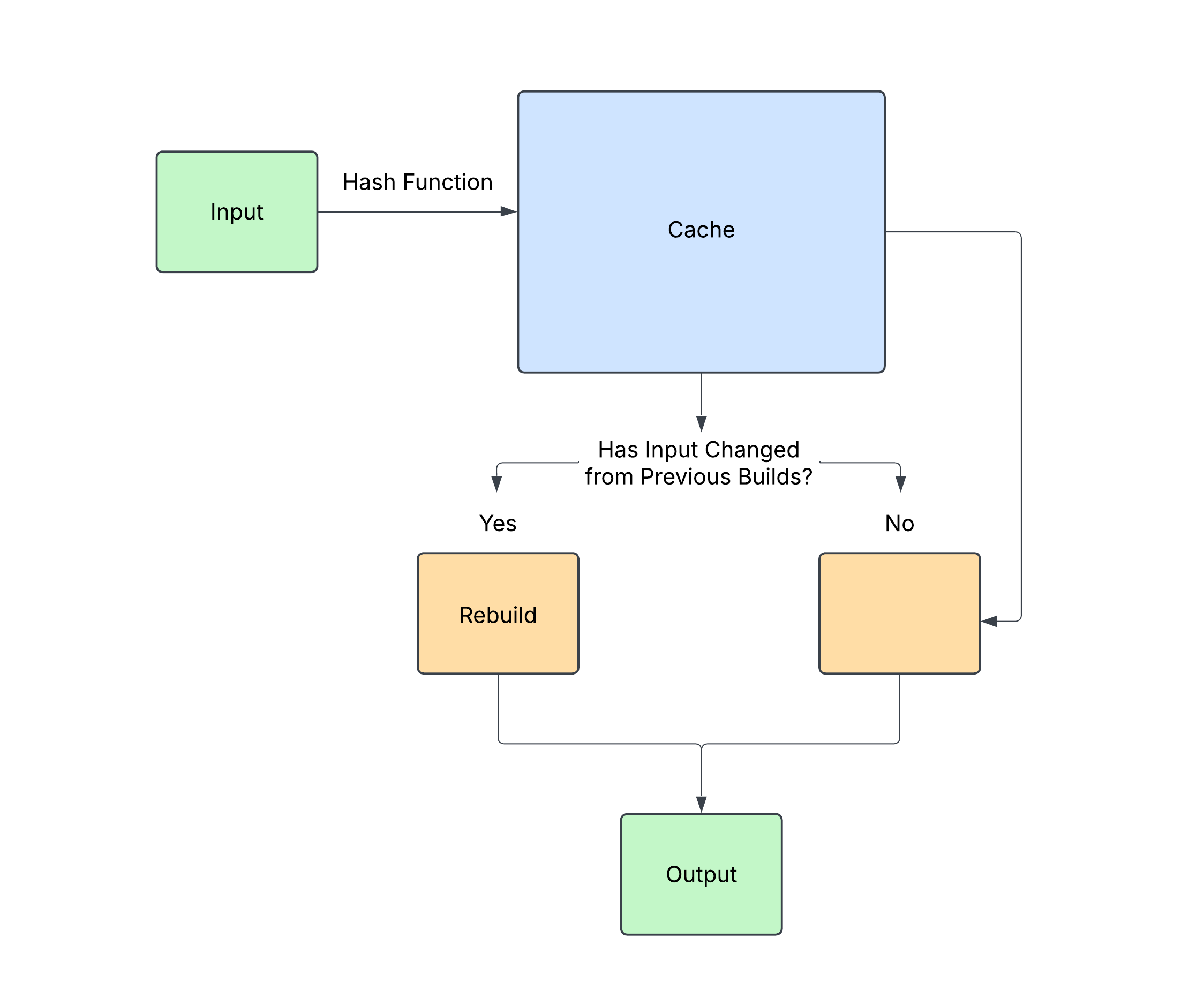
This efficiency is further amplified when Bazel is paired with a remote cache, enabling a multi-layered caching system (in-memory, on-disk, and remote) that according to Google “routinely achieves cache hit rates north of 99%.” Tools like NativeLink can provide the remote cache layer, allowing Bazel to offload build artifacts and speed up workflows.
Parallelism
Because Bazel is stateless and has a byte-level understanding of dependencies, it knows exactly which actions can run independently. This allows it to scale builds in two powerful ways:
- Locally, by using all available CPU cores to run parallel executions on a developer’s machine.
- Remotely, by distributing the workload across a cluster of machines using Remote Build Execution.
.png)
Optimizing even further, Bazel supports dynamic execution, where it runs actions both locally and remotely at the same time — using whichever build finishes first and canceling out the other.
Scales with Your Tech Stack
Bazel’s commitment to packaging code into sandboxed builds makes it capable of supporting a wide range of technologies, including:
- Languages like Java, Python, Go, C++, TypeScript, Rust, Kotlin, Scala, and more.
- Operating systems such as Linux, macOS, Windows, Android, and iOS.
To make it even more extensible, Bazel operates using Starlark, a Python-like language that allows teams to write custom rules or extend existing ones to conform to their niche environments.
To summarize, Bazel’s core principle of determinism directly leads to its capabilities of correctness, caching, and speed at scale, no matter the environment.
Now that we’ve seen what Bazel does, let’s take a closer look at how it actually works.
How Bazel Works Under the Hood
Bazel’s power comes from how it structures and processes your build code.
It Starts with Your Module
Every Bazel project begins with a MODULE.bazel file. This file declares external dependencies and integrates them into your build using the blzmod system, Bazel’s modern module system for managing dependencies.
Code is Organized into Packages
Packages break your project down into smaller, structured units. A package is any directory with a BUILD.bazel file, which declares all of the targets that can be built — think of it like a Makefile or manifest.
But why does this matter? Bazel needs to track dependencies at a granular level, and packages provide clear boundaries. So rather than working with individual files, Bazel can reason about your code in modular, manageable chunks.
Packages Define Targets
A target is a single unit of work — whether that’s compiling a library, running a test, or generating a file. Targets are defined using rules written in Starlark and specify what to build, how to build it, and what it depends on.
A target is an instantiation of a rule that defines what to build and how. Each target produces one or more actions, which are the actual units of work Bazel executes (compiling a library, running a test, etc.).
Bazel isolates the actions that make your builds, allowing it to run them independently and track exactly how different parts of your build relate to one another.
This All Leads to the Action Graph
Everything defined in your module, packages, and build targets ultimately feeds into Bazel’s action graph.
The graph is structured as a Directed Acyclic Graph (DAG) where:
- Each node represents an individual action. These actions are generated by a target, which are instantiated by rules in your build.
- Each edge represents a declared dependency between actions.
To build the action graph, Bazel:
- Parses all
BUILD.bazelfiles to locate targets. - Analyzes the declared dependencies between those targets.
- Constructs a DAG representing the actions required to complete the build.
- Associates each action with its declared inputs and outputs, along with the applicable rule.
.png)
The Action Graph Allows Bazel to:
- Be Incremental.
- Bazel walks through the graph to determine what has changed (and what hasn’t). By comparing input hashes to previous Bazel caches, it can skip any actions (including tests) that are unaffected.
- Be Parallel.
- Independent actions are easily identified in the graph because of Bazel’s explicit dependency declarations. These actions are then run in parallel — safely and efficiently, without the risk of race conditions.
Conclusion
Putting it all together, Bazel was built on the principles of determinism and correctness. By treating builds as a series of isolated actions, companies like Google, Stripe, and Dropbox are able to scale their massive codebases in an efficient and reliable manner.
But just like any powerful tool, Bazel works best when paired with the right infrastructure. It knows how to build action graphs, execute builds in parallel, and check caches, but it doesn’t provide the backend systems that actually run these actions.
That’s where NativeLink comes in. NativeLink complements Bazel by providing:
- A distributed multi-layer remote cache, built on content-addressable storage (CAS), so Bazel can store previous build artifacts across machines
- A remote execution backend that schedules and executes actions on distributed worker nodes, as directed by Bazel
- A scalable platform that supports high-throughput builds and parallel execution
To sum it up, Bazel provides the protocol and NativeLink provides the platform that turns Bazel into a true distributed build system.